AI agents require models to execute multi-step reasoning chains while maintaining constraint adherence, tool usage accuracy, and factual consistency. Pre-training on broad corpora leaves capability gaps, especially in specialized workflows requiring multi-step reasoning, constraint adherence, and domain-specific tool orchestration. While supervised fine-tuning (SFT) can address some gaps, it requires extensive labeled trajectory data.
Case Study
How reinforcement learning improved quality by 16% in a real-world meal planning application
—
+25.8% increase in quality
compared to baseline models

We developed an automated reinforcement fine-tuning pipeline applied to Mealworm, an open-source meal planning agent. Our system eliminates manual data labeling by learning directly from production traces: ingesting agent interactions, parsing trajectories with proprietary algorithms, and applying custom reward models to generate training signals. This approach enables continuous model improvement as real-world usage generates new training examples.
Key Results:
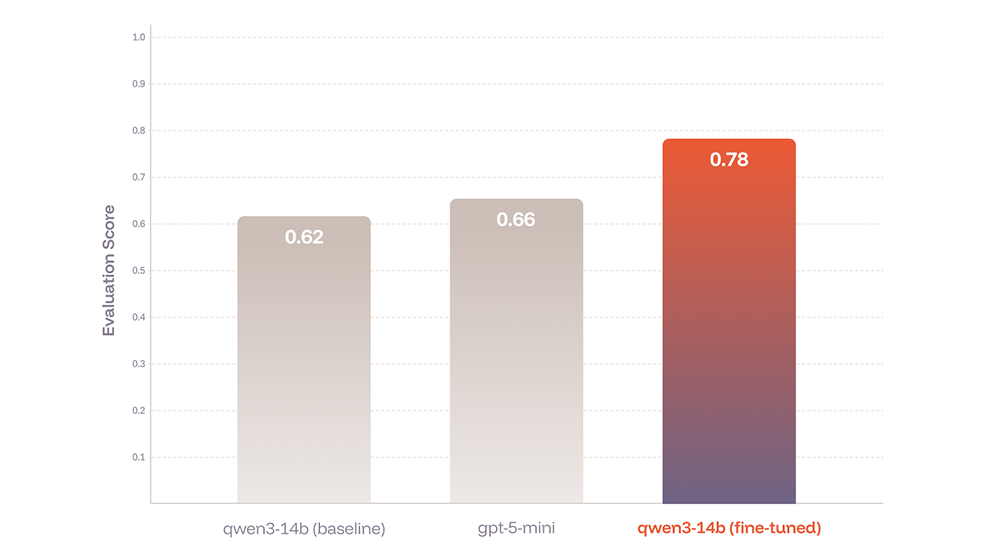
The fine-tuned qwen3-14b achieved a +25.8% relative improvement over its baseline (+0.16 absolute increase) and outperformed gpt-5-mini by +18.2% (+0.12 absolute), demonstrating that targeted reinforcement learning enables smaller models to exceed larger alternatives on specialized tasks.
System Architecture
Automated Reinforcement Fine-tuning Pipeline
Our system comprises four stages that continuously improve model performance from production data, building on the ART (Agent Reinforcement Tuning) framework:
Trace Ingestion: Quotient Tracing captures the full agent execution including user queries, intermediate reasoning steps and tool calls.
Trace Processing: Proprietary parsing algorithms segment raw traces into discrete episodes, extract state transitions, and identify decision points at step-level granularity.
Reward Evaluation: Custom reward models score each trajectory based on criteria designed specifically for meal planning agent assessment.
RL Fine-Tuning: The system applies reinforcement learning using reward signals to adjust model behavior across trajectory steps.
Reward Model Design
The core component of Quotient's RFT pipeline is the reward model, which is customized to reinforce specific behaviors for the particular agent application. Unlike general-purpose reward models, these domain-specific evaluators encode detailed understanding of what constitutes effective agent behavior within the target workflow.
For the Mealworm meal planning agent, the reward model evaluates the quality of each model response given the overall agent's goals and the user's stated preferences. This evaluation framework assesses whether individual responses advance task completion while respecting user constraints and other requirements.
The reward model assigns low scores to trajectories that contain any errors, hallucinations or that violate any instructions, regardless of their progress towards the goal. This prioritization teaches the model that correctness is more valuable than completion speed.
This behavior-specific reward design allows the pipeline to continuously improve model performance on the exact capabilities required for production deployment, learning directly from real-world interaction patterns without manual annotation.
Results and Analysis
In just four training steps–using 256 training data points pulled from production traces–we improved the model from 0.62 to 0.78, a substantial 16-percentage-point gain in trajectory quality.
More significantly, the fine-tuned model surpassed gpt-5-mini (evaluation score = 0.66), demonstrating that targeted reinforcement learning can produce specialized models that outperform larger general-purpose models on specific tasks.
Through reinforcement fine-tuning, the model developed stronger capabilities in:
- Constraint adherence: Better recognition and consistent application of task-specific rules across multi-step sequences, including maintaining dietary restrictions, respecting caloric targets, and adhering to ingredient availability constraints.
- Error Reduction: Decreased frequency of hallucinated information, malformed outputs, and incorrect tool invocations compared to baseline.
- Tool Usage Precision: More accurate selection and invocation of available functions
- Workflow efficiency: Fewer redundant steps while maintaining thoroughness
Conclusion
These results suggest several important takeaways for developers building agentic applications:
Specialization over scale: For domain-specific tasks, a smaller model trained with reinforcement learning can outperform larger general-purpose models, reducing inference costs and latency.
Behavior shaping matters: Explicitly defining and rewarding desired behaviors through reinforcement learning can address failure modes that persist even after extensive pre-training and supervised fine-tuning.
Error prevention is learnable: Models can learn to prioritize correctness over completion, an essential capability for reliable agent systems.
Automated improvement at scale: By building pipelines that learn directly from production data, teams can continuously improve model performance without manual intervention.
Reinforcement fine-tuning offers a promising path toward more reliable AI agents. By explicitly teaching models what constitutes good agent behavior through an automated pipeline, we achieved substantial improvements in trajectory quality — enough to enable an open-source model to surpass larger, closed-source alternatives.
For developers building agentic applications, these results suggest that investing in targeted reinforcement learning can yield significant returns, producing specialized models that are both more capable and more efficient than off-the-shelf alternatives. The automated nature of the pipeline makes this approach practical and scalable for real-world production environments.
.avif)
No items found.