Turn your AI agents into experts
Quotient transforms your static models into evolving agents that learn in production and specialize in your domain.
One-time 5-minute setup
Improvement never stops













It’s time to build AI
the right way
The impact of post-training intelligence
Monitor, evaluate, and reinforce
your agents, automatically
Plug in to stream telemetry
Connect Quotient to your agents in minutes, and give them the awareness to learn from real-world data.
Detect issues instantly
Evaluator models track interactions, spotting reasoning errors, hallucinations, and regressions before they impact users.
Learn from each interaction
Every interaction is training data. Quotient fine-tunes and redeploys stronger models continuously.
Specialized agents across industries

Coding
+12% increased accuracy for code generation and tool use

Finance
+15% fewer critical errors in financial analysis workflows

Legal
+18% higher first-pass acceptance for legal drafts

Customer Support
15% fewer escalations with faster issue resolution

Marketing
-18% less manual editing for generated content

Security Incident Response
+15% faster incident resolution with fewer procedural errors

Sales
+10% more consistent follow-ups across sales workflows

SREs
12% fewer runbook errors during on-call incidents
Created by
engineers behind
GitHub Copilot
While working on GitHub's telemetry and evaluation systems, we saw firsthand how real-world feedback makes AI sharper, safer, and more useful.
We founded Quotient to bring that same continuous learning capability to every engineering team that's pushing the edges of artificial intelligence.

Julia Neagu
CEO

Freddie Vargus
CTO
Leading AI teams build with Quotient
"Quotient has been a real game-changer and is now an essential part of our infrastructure stack. Having this high level of monitoring and transparency has even factored into our investor due diligence conversations. Our users trust us to have the best AI search solution, and we trust Quotient."

Rotem Weiss
CEO & Co-Founder of Tavily
“Setup was 10x easier than comparable tools like Weave, and the feedback is much more actionable: instead of flagging tons of tiny semantic/borderline issues, it makes it clear what’s actually wrong and worth fixing.”

Principal AI Product Lead
Public-interest government data organization
“We work with sensitive, high-context AI use cases, so hallucinations are a real reputational risk. Quotient gives us visibility into when and why hallucinations happen, so we can catch and fix them early. That level of monitoring helps us build trust with our customers and their end users, who expect perfection.”

Mishkin Berteig
CEO & Founder of MaxGood.work
“Quotient's platform enables us to conduct fast experimentations within our system, whether related to our generative models or influenced by our retrieval system and data pipeline. We can quickly connect these individual components back to the overall product, resulting in high quality for our customers.”
.avif)
Hao Sheng
CEO & Founder of Expertise AI
“We want to ship the best product possible and make sure our assistant doesn’t hallucinate. We’re making big changes to chunking/retrieval, and Quotient is the fastest way to verify what we’ve built, surface issues, and keep improving (especially when we swap models). Brilliant platform.”
Co-founder & Head of Development
AI customer support assistant
"Quotient has been a real game-changer and is now an essential part of our infrastructure stack. Having this high level of monitoring and transparency has even factored into our investor due diligence conversations. Our users trust us to have the best AI search solution, and we trust Quotient."
Rotem Weiss
CEO & Co-Founder of Tavily
“Setup was 10x easier than comparable tools like Weave, and the feedback is much more actionable: instead of flagging tons of tiny semantic/borderline issues, it makes it clear what’s actually wrong and worth fixing.”
Principal AI Product Lead
Public-interest government data organization
“We work with sensitive, high-context AI use cases, so hallucinations are a real reputational risk. Quotient gives us visibility into when and why hallucinations happen, so we can catch and fix them early. That level of monitoring helps us build trust with our customers and their end users, who expect perfection.”
Mishkin Berteig
CEO & Founder of MaxGood.work
“Quotient's platform enables us to conduct fast experimentations within our system, whether related to our generative models or influenced by our retrieval system and data pipeline. We can quickly connect these individual components back to the overall product, resulting in high quality for our customers.”
Hao Sheng
CEO & Founder of Expertise AI
“We want to ship the best product possible and make sure our assistant doesn’t hallucinate. We’re making big changes to chunking/retrieval, and Quotient is the fastest way to verify what we’ve built, surface issues, and keep improving (especially when we swap models). Brilliant platform.”
Co-founder & Head of Development
AI customer support assistant










How reinforcement learning improved quality by 16% in a real-world meal planning application
We applied reinforcement fine-tuning to qwen3-14b to optimize its performance on agentic workflows within Mealworm, an open-source meal planning application. Our results demonstrate that domain-specific reinforcement learning can substantially improve model reliability on multi-step reasoning tasks.
Full Case Study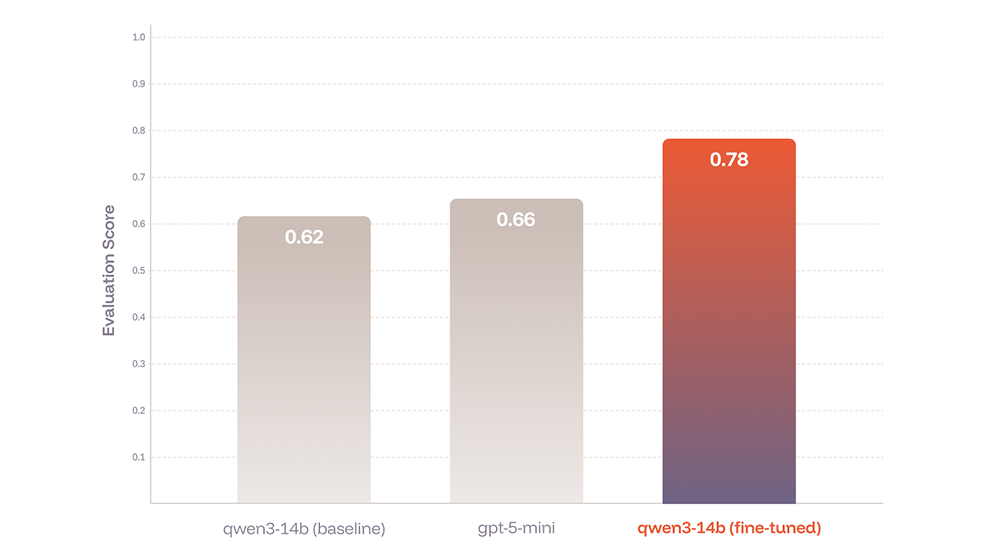
+25.8% increase in quality
compared to baseline models
Quotient
Cookbooks
Dive into how to use Quotient to monitor, evaluate, and improve AI systems in production.
Latest Articles
Subscribe to the Quotient Newsletter to get practical insights and cutting-edge research, straight into your inbox:
Common Questions
If you have a burning question that we haven’t answered in this list, reach out and ask us directly.
How long does integration take?
Most teams are up and running in minutes. Quotient integrates via a lightweight SDK and OpenTelemetry-based tracing, often requiring only a few lines of code. Once traces are flowing, detections, reports, and alerts can be enabled incrementally.
What does integration actually involve?
You instrument your agents with OpenTelemetry (via OpenInference or supported agent frameworks). Quotient ingests traces and automatically runs Limbic detections, reporting, and monitoring on top of them, with no changes to your agent logic required.
Do you support SaaS, VPC, and on-prem deployments?
Yes. SaaS is the fastest way to get started. For stricter security or data residency requirements, we support private VPC and on-prem deployments using Kubernetes-based infrastructure.
How is the platform priced?
Pricing is based on usage (logs, detections, training runs) and deployment model. Reinforcement learning features and custom reward models are available on higher tiers. See the pricing page or contact sales@quotientai.co for details.
What does a pilot look like?
Pilots typically focus on one or two production agents. We define reliability goals (e.g. tool-use accuracy, hallucination reduction, retrieval relevance), run Limbic detections on real traces, and demonstrate measurable improvement before expanding usage or enabling reinforcement learning.
How does this compare to DIY or consulting-heavy approaches?
Teams use Quotient to avoid building and maintaining custom tracing pipelines, evaluator models, reporting logic, and RL infrastructure. Limbic provides an end-to-end learning loop: from production signals to model improvement, right out of the box.
Which models and agent frameworks do you support?
Quotient is model-agnostic and works with OpenAI, Anthropic, and open-source models (e.g. Qwen). We support common agent frameworks and function/tool-calling workflows, ingesting telemetry directly from your existing stack.
What does Limbic actually measure?
Limbic evaluates real agent behavior across full trajectories, including: Hallucinations, Retrieval relevance, Tool-use correctness, and Failure patterns across sessions.
How is this different from guardrails or rules?
Instead of static rules, Limbic uses learned evaluator models that understand context across multi-step interactions. This allows it to detect subtle failures humans and simple heuristics miss.
How does Quotient use reinforcement learning?
Limbic automatically extracts reward signals from agent traces by identifying successful and failed behaviors. These signals are used to fine-tune models without manual labeling or handcrafted reward functions.
Can you build custom reward or detection models?
Yes. For Evolve enterprise plans, we build domain-specific reward and detection models tailored to your use case, validated on your real production data before rollout.
Do we get access to the fine-tuned models?
Yes. You can use fine-tuned models via hosted inference endpoints or receive model weights for self-hosting, depending on your deployment setup.
What scale does Quotient support?
Quotient supports everything from early production agents to systems generating millions of traces per day. SaaS minimizes operational overhead, while VPC/on-prem deployments provide full control at scale.
How is sensitive data handled?
Enterprise deployments support strict isolation, private networking, and controlled data retention. Traces remain within your chosen environment, and access is governed by your infrastructure and security policies.