Contact sales

Evaluate, improve and ship high-quality AI products through fast experimentation cycles.
Thank you!
Your submission has been received!
Your submission has been received!
Oops! Something went wrong while submitting the form.
Our work spans cutting-edge research, practical tools like our LLM evaluation libraries, and comprehensive implementation guides.
From academic insights that advance the field to production-ready solutions that solve immediate challenges.
This notebook shows how to build a LangChain-based research assistant powered by Tavily and OpenAI. The agent answers real-world search queries using live web content via Tavily tools, and is monitored using Quotient AI to detect hallucinations, irrelevant retrievals, and other failure modes.
judges is a small open-source library to use and create LLM-as-a-Judge evaluators. The purpose of judges is to have a curated set of LLM evaluators in a low-friction format across a variety of use cases that are backed by research, and can be used off-the-shelf or serve as inspiration for building your own LLM evaluators.
.png)
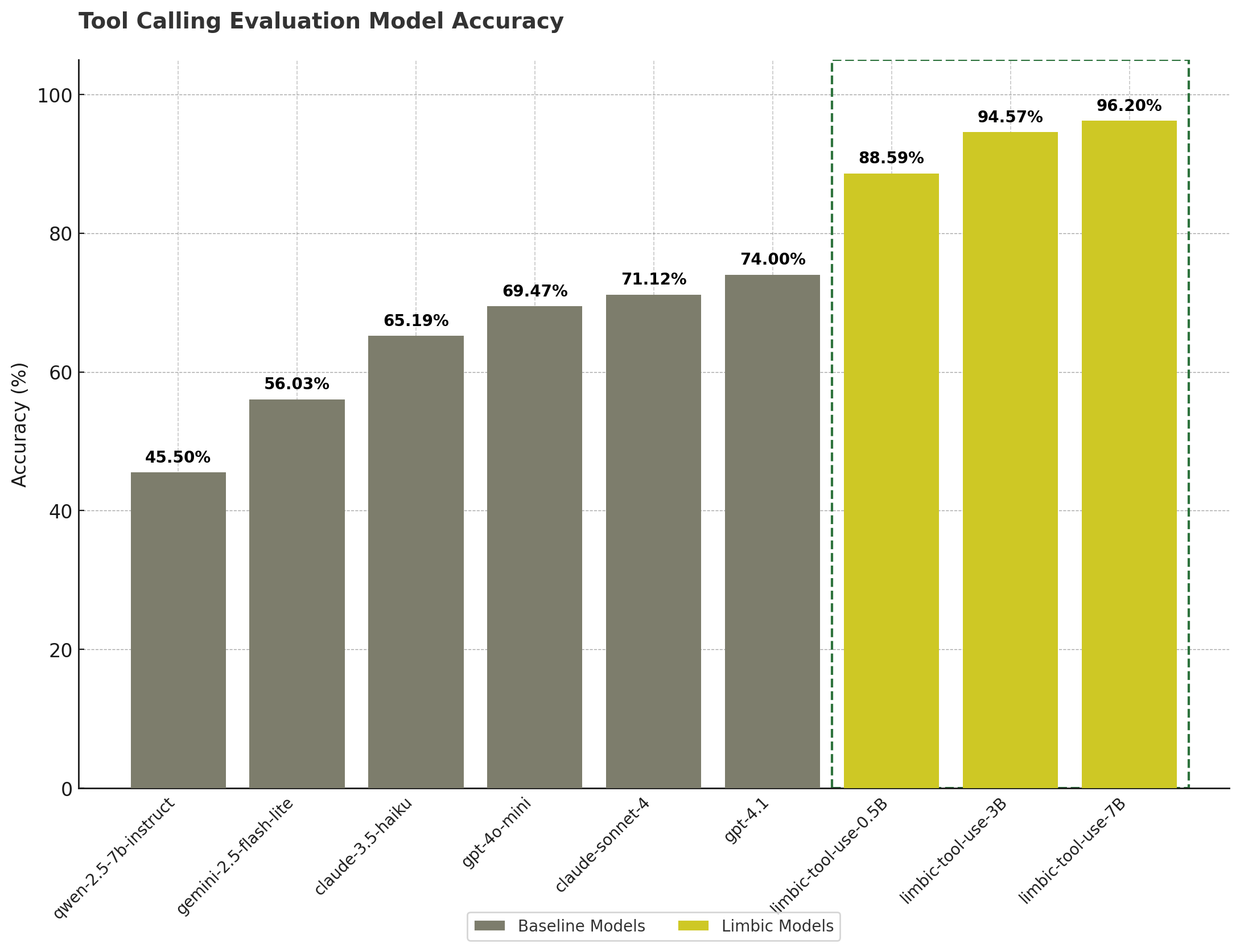
We've released limbic-tool-use-0.5B, a small model (0.5B parameters) for detecting tool use errors in agents. It was trained on 50M tokens from publicly available MCP server tools and is designed to catch issues like invalid tool calls, misinterpreted responses, and broken sequences. Despite its size, it achieves 88.59% accuracy, significantly outperforming GPT-4.1 (74.0%) and Claude Sonnet (71.12%).
As large language models (LLMs) are increasingly adopted in critical industries, ensuring their outputs are factually grounded has emerged as a major concern. One prominent issue is "hallucination," where models generate content unsupported by or contrary to the provided evidence. Existing hallucination detection benchmarks are often limited, synthetic, or narrowly focused on specific tasks like question-answering. Recognizing this gap, we developed HalluMix: a task-agnostic, multi-domain benchmark designed to evaluate hallucination detection in realistic, diverse contexts.

Retrieval Augmented Generation (RAG) has become a cornerstone for integrating domain-specific content and addressing hallucinations in AI applications. As the adoption of RAG solutions intensifies across industries, a pressing challenge emerges: understanding and identifying where within the complex RAG framework changes and improvements can be made. Join Quotient AI and Qdrant as we navigate an end-to-end process for RAG experimentation and evaluation, offering insights into optimizing performance and addressing hurdles along the RAG implementation journey.
Evaluating large language model (LLM) outputs efficiently and accurately – especially for domain-specific tasks – remains a significant challenge in AI development. We present Subject-Matter Expert Language Liaison (SMELL), a novel framework that combines human expertise with LLM capabilities to automatically create feedback-informed LLM judges. SMELL addresses the limitations of generic LLM judges while maintaining scalability through a four-stage pipeline: data annotation by human experts, feedback synthesis, rubric generation, and evaluation using the generated rubric.judges uses SMELL as part of its autojudge method.

In this talk, Quotient AI and Tavily share a practical framework for evaluating AI search systems that operate in real-time, web-based environments. Static benchmarks fall short when the web is constantly changing and user queries are open-ended. We demonstrate how dynamic evaluation datasets, combined with reference-free metrics like hallucination detection, document relevance, and answer completeness, reveal failure modes traditional tests miss. This approach helps teams building AI agents—whether for legal search, sports updates, or coding assistance—continuously improve performance in production.

Realistic, domain-specific evaluation is the most impactful step AI developers can take to make their products practical and reduce deployment risks. Benchmarks are a good starting point, but they often don’t reflect how generative AI performs in everyday use. In this talk, we’ll show how you can use the data you already have in your enterprise to create reference datasets that fit your specific use cases, domains, and organizational knowledge. By tapping into this data, we can test foundational LLMs on key tasks like customer support and product catalog Q&A. We'll also show results on how significantly performance in real-world settings differs from benchmark predictions, and how to use that knowledge to build better AI products.

Have feedback, ideas, or requests?
Be part of the future!
Email us at research@quotientai.co and help shape the next wave of AI advancements!

